
O uso do conteúdo da Web pelo ChatGPT é justo?
Alguns se sentem desconfortáveis com a forma como o ChatGPT usa seu conteúdo da web para treinar e aprender com
- Existe uma maneira de impedir que seu conteúdo seja usado para treinar grandes modelos de linguagem como o ChatGPT
- Especialista em Lei de Propriedade Intelectual diz que a tecnologia ultrapassou a capacidade das leis de direitos autorais de acompanhar
- Um especialista em marketing de busca questiona se o uso de conteúdo da Internet por IA sem permissão é justo
Os Large Language Models (LLMs) como o ChatGPT são treinados usando várias fontes de informação, incluindo conteúdo da web. Esses dados formam a base dos resumos desse conteúdo na forma de artigos que são produzidos sem atribuição ou benefício para quem publicou o conteúdo original usado para o treinamento do ChatGPT.

Os mecanismos de pesquisa baixam o conteúdo do site (chamado rastreamento e indexação) para fornecer respostas na forma de links para os sites.
Os editores de sites podem optar por não ter seu conteúdo rastreado e indexado pelos mecanismos de pesquisa por meio do Protocolo de Exclusão de Robôs, comumente referido como Robots.txt.
O Protocolo de Exclusões de Robôs não é um padrão oficial da Internet, mas é um que os rastreadores da Web legítimos obedecem.
Os editores da web devem poder usar o protocolo Robots.txt para impedir que modelos de linguagem grandes usem o conteúdo do site?
Grandes modelos de linguagem usam o conteúdo do site sem atribuição
Algumas pessoas envolvidas com marketing de busca se sentem desconfortáveis com a forma como os dados do site são usados para treinar máquinas sem dar nada em troca, como reconhecimento ou tráfego.
Hans Petter Blindheim ( perfil do LinkedIn ), especialista sênior da Curamando, compartilhou suas opiniões comigo.
Hans Petter comentou:
“Quando um autor escreve algo depois de ter aprendido algo com um artigo em seu site, na maioria das vezes ele irá criar um link para seu trabalho original porque oferece credibilidade e cortesia profissional.
Chama-se citação.
Mas a escala em que o ChatGPT assimila o conteúdo e não dá nada em troca o diferencia tanto do Google quanto das pessoas.
Um site geralmente é criado com uma diretiva de negócios em mente.
O Google ajuda as pessoas a encontrar o conteúdo, fornecendo tráfego, o que traz benefícios mútuos.
Mas não é como se grandes modelos de linguagem pedissem sua permissão para usar seu conteúdo, eles apenas o usavam em um sentido mais amplo do que o esperado quando seu conteúdo foi publicado.
E se os modelos de linguagem AI não oferecem valor em troca, por que os editores devem permitir que eles rastreiem e usem o conteúdo?
O uso do seu conteúdo atende aos padrões de uso justo?
Quando o ChatGPT e os próprios modelos de ML/AI do Google treinam em seu conteúdo sem permissão, giram o que aprendem lá e usam isso enquanto mantêm as pessoas longe de seus sites – a indústria e também os legisladores não deveriam tentar retomar o controle da Internet forçando eles para fazer a transição para um modelo “opt-in”?”
As preocupações que Hans Petter expressa são razoáveis.
À luz da rapidez com que a tecnologia está evoluindo, as leis relativas ao uso justo devem ser reconsideradas e atualizadas?
Perguntei a John Rizvi, um advogado de patentes registrado ( perfil do LinkedIn ) que é certificado em Lei de Propriedade Intelectual, se as leis de direitos autorais da Internet estão desatualizadas .
João respondeu:
“Sim, sem dúvida.
Um grande ponto de discórdia em casos como este é o fato de que a lei inevitavelmente evolui muito mais lentamente do que a tecnologia.
Nos anos 1800, isso talvez não importasse tanto porque os avanços eram relativamente lentos e, portanto, o mecanismo legal era mais ou menos preparado para corresponder.
Hoje, no entanto, os avanços tecnológicos descontrolados ultrapassaram em muito a capacidade da lei de acompanhar.
Existem simplesmente muitos avanços e muitas partes móveis para a lei acompanhar.
Como atualmente é constituído e administrado, em grande parte por pessoas que dificilmente são especialistas nas áreas de tecnologia que estamos discutindo aqui, a lei está mal equipada ou estruturada para acompanhar o ritmo da tecnologia…e devemos considerar que este não é um coisa ruim.
Portanto, em um aspecto, sim, a lei de Propriedade Intelectual precisa evoluir, mesmo que pretenda, e muito menos esperar, acompanhar os avanços tecnológicos.
O problema principal é encontrar um equilíbrio entre manter-se atualizado com as várias formas de tecnologia que podem ser usadas, evitando o exagero flagrante ou a censura total para ganhos políticos envoltos em intenções benevolentes.
A lei também deve tomar cuidado para não legislar contra os possíveis usos da tecnologia de forma tão ampla a ponto de estrangular qualquer benefício potencial que possa derivar deles.
Você poderia facilmente entrar em conflito com a Primeira Emenda e qualquer número de casos resolvidos que circunscrevam como, por que e em que grau a propriedade intelectual pode ser usada e por quem.
E tentar visualizar todo uso concebível de tecnologia anos ou décadas antes que a estrutura exista para torná-la viável ou mesmo possível seria uma tarefa tola extremamente perigosa.
Em situações como essa, a lei realmente não pode deixar de ser reativa à forma como a tecnologia é usada… não necessariamente como ela foi planejada.
Não é provável que isso mude tão cedo, a menos que atinjamos um platô tecnológico maciço e imprevisto que permita que a lei tenha tempo para acompanhar os eventos atuais.
Portanto, parece que a questão das leis de direitos autorais tem muitas considerações a serem ponderadas quando se trata de como a IA é treinada, não há uma resposta simples.
OpenAI e Microsoft processadas
Um caso interessante que foi arquivado recentemente é aquele em que a OpenAI e a Microsoft usaram código-fonte aberto para criar seu produto CoPilot.
O problema com o uso de código-fonte aberto é que a licença Creative Commons requer atribuição.
De acordo com um artigo publicado em uma revista acadêmica:
“Os queixosos alegam que OpenAI e GitHub montaram e distribuíram um produto comercial chamado Copilot para criar código generativo usando código acessível ao público originalmente disponibilizado sob várias licenças de estilo “código aberto”, muitas das quais incluem um requisito de atribuição.
Como afirma o GitHub, ‘…[t]oido em bilhões de linhas de código, o GitHub Copilot transforma prompts de linguagem natural em sugestões de codificação em dezenas de idiomas.’
O produto resultante supostamente omitiu qualquer crédito aos criadores originais.”
O autor desse artigo, que é um especialista jurídico no assunto de direitos autorais, escreveu que muitos veem as licenças Creative Commons de código aberto como um “vale para todos”.
Alguns também podem considerar a frase free-for-all uma descrição justa dos conjuntos de dados compostos por conteúdo da Internet que são copiados e usados para gerar produtos de IA como o ChatGPT.
Histórico sobre LLMs e conjuntos de dados
Grandes modelos de linguagem são treinados em vários conjuntos de dados de conteúdo. Os conjuntos de dados podem consistir em e-mails, livros, dados do governo, artigos da Wikipédia e até mesmo conjuntos de dados criados de sites vinculados a postagens no Reddit que tenham pelo menos três votos positivos.
Muitos dos conjuntos de dados relacionados ao conteúdo da Internet têm origem no rastreamento criado por uma organização sem fins lucrativos chamada Common Crawl .
Seu conjunto de dados, o conjunto de dados Common Crawl, está disponível gratuitamente para download e uso.
O conjunto de dados Common Crawl é o ponto de partida para muitos outros conjuntos de dados criados a partir dele.
Por exemplo, o GPT-3 usou uma versão filtrada do Common Crawl ( PDF de Modelos de idioma são poucos alunos ).
Foi assim que os pesquisadores do GPT-3 usaram os dados do site contidos no conjunto de dados Common Crawl:
“Os conjuntos de dados para modelos de linguagem se expandiram rapidamente, culminando no conjunto de dados Common Crawl… constituindo quase um trilhão de palavras.
Esse tamanho de conjunto de dados é suficiente para treinar nossos maiores modelos sem nunca atualizar na mesma sequência duas vezes.
No entanto, descobrimos que versões não filtradas ou levemente filtradas do Common Crawl tendem a ter qualidade inferior do que conjuntos de dados mais selecionados.
Portanto, tomamos 3 passos para melhorar a qualidade média de nossos conjuntos de dados:
(1) baixamos e filtramos uma versão do CommonCrawl com base na semelhança com uma variedade de corpora de referência de alta qualidade,
(2) realizamos desduplicação difusa no nível do documento, dentro e entre conjuntos de dados, para evitar redundância e preservar a integridade de nosso conjunto de validação mantido como uma medida precisa de superajuste e
(3) também adicionamos corpora de referência de alta qualidade conhecidos ao mix de treinamento para aumentar o CommonCrawl e aumentar sua diversidade.”
O conjunto de dados C4 do Google (Colossal, Cleaned Crawl Corpus), que foi usado para criar o Text-to-Text Transfer Transformer (T5), também tem suas raízes no conjunto de dados Common Crawl.
Seu trabalho de pesquisa ( Explorando os limites do aprendizado de transferência com um PDF unificado de transformador de texto para texto ) explica:
“Antes de apresentar os resultados de nosso estudo empírico em larga escala, revisamos os tópicos básicos necessários para entender nossos resultados, incluindo a arquitetura do modelo Transformer e as tarefas de downstream que avaliamos.
Também apresentamos nossa abordagem para tratar cada problema como uma tarefa de texto para texto e descrevemos nosso “Colossal Clean Crawled Corpus” (C4), o conjunto de dados baseado em rastreamento comum que criamos como uma fonte de dados de texto não rotulados.
Referimo-nos ao nosso modelo e estrutura como o ‘Transformador de transferência de texto para texto’ (T5).”
O Google publicou um artigo em seu blog de IA que explica melhor como os dados do Common Crawl (que contém conteúdo extraído da Internet) foram usados para criar o C4.
Eles escreveram:
“Um ingrediente importante para o aprendizado de transferência é o conjunto de dados não rotulado usado para pré-treinamento.
Para medir com precisão o efeito de aumentar a quantidade de pré-treinamento, é necessário um conjunto de dados que não seja apenas de alta qualidade e diverso, mas também massivo.
Os conjuntos de dados pré-treinamento existentes não atendem a todos esses três critérios – por exemplo, o texto da Wikipedia é de alta qualidade, mas uniforme em estilo e relativamente pequeno para nossos propósitos, enquanto os rascunhos da Web do Common Crawl são enormes e altamente diversos, mas razoavelmente baixa qualidade.
Para atender a esses requisitos, desenvolvemos o Colossal Clean Crawled Corpus (C4), uma versão limpa do Common Crawl que é duas ordens de grandeza maior que a Wikipedia.
Nosso processo de limpeza envolvia desduplicação, descarte de frases incompletas e remoção de conteúdo ofensivo ou ruidoso.
Essa filtragem levou a melhores resultados em tarefas de downstream, enquanto o tamanho adicional permitiu que o tamanho do modelo aumentasse sem overfitting durante o pré-treinamento.”
Google, OpenAI e até os dados abertos da Oracle estão usando o conteúdo da Internet, seu conteúdo, para criar conjuntos de dados que são usados para criar aplicativos de IA como o ChatGPT.
O rastreamento comum pode ser bloqueado
É possível bloquear o rastreamento comum e, posteriormente, optar por não participar de todos os conjuntos de dados baseados no rastreamento comum.
Mas se o site já foi rastreado, os dados do site já estão nos conjuntos de dados. Não há como remover seu conteúdo do conjunto de dados Common Crawl e de qualquer um dos outros conjuntos de dados derivados, como C4 e Open Data.
O uso do protocolo Robots.txt apenas bloqueará rastreamentos futuros pelo Common Crawl, não impedirá que os pesquisadores usem o conteúdo já existente no conjunto de dados.
Como bloquear rastreamento comum de seus dados
O bloqueio do Rastreamento Comum é possível por meio do uso do protocolo Robots.txt, dentro das limitações discutidas acima.
O bot Common Crawl é chamado CCBot.
Ele é identificado usando a string CCBot User-Agent mais atualizada: CCBot/2.0
O bloqueio do CCBot com Robots.txt é feito da mesma forma que com qualquer outro bot.
Aqui está o código para bloquear CCBot com Robots.txt.
Agente do usuário: CCBot Não permitir: /
O CCBot rastreia a partir de endereços IP da Amazon AWS.
CCBot também segue a meta tag nofollow Robots:
<meta name="robots" content="nofollow">
E se você não estiver bloqueando o rastreamento comum?
O conteúdo da Web pode ser baixado sem permissão, que é como os navegadores funcionam, eles baixam o conteúdo.
O Google ou qualquer outra pessoa não precisa de permissão para baixar e usar o conteúdo publicado publicamente.
Os editores de sites têm opções limitadas
A consideração de se é ético treinar IA em conteúdo da web não parece fazer parte de nenhuma conversa sobre a ética de como a tecnologia de IA é desenvolvida.
Parece ser um dado adquirido que o conteúdo da Internet pode ser baixado, resumido e transformado em um produto chamado ChatGPT.
Isso parece justo? A resposta é complicada.


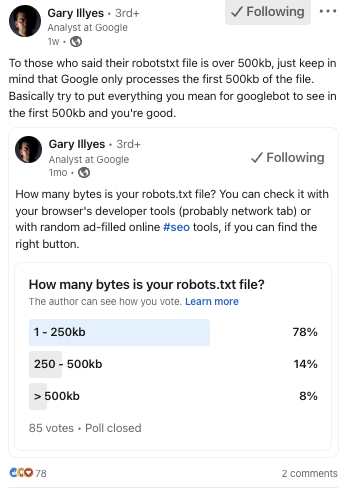 Captura de tela de: linkedin.com/in/garyillyes/, janeiro de 2023.
Captura de tela de: linkedin.com/in/garyillyes/, janeiro de 2023.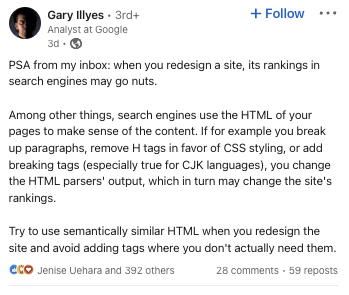 Captura de tela de: linkedin.com/in/garyillyes/, janeiro de 2023.
Captura de tela de: linkedin.com/in/garyillyes/, janeiro de 2023.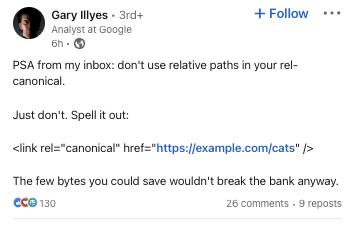 Captura de tela de: linkedin.com/in/garyillyes/, janeiro de 2023.
Captura de tela de: linkedin.com/in/garyillyes/, janeiro de 2023.