
Veja nesse artigo o que é o Robots txt, um arquivo de texto (não html) que você coloca no seu site para informar aos robôs de pesquisa quais páginas você gostaria que eles não visitassem.
Olá, sou Lucas Cruz e neste artigo vou lhe mostrar o que é o Robots txt.

Acesse o curso – expertdigital.net/curso-de-search-console/
Robots.txt
É ótimo quando os motores de busca freqüentemente visitam seu site e indexam seu conteúdo, mas muitas vezes há casos em que a indexação de partes de seu conteúdo on-line não é o que você quer. Por exemplo, se você tiver duas versões de uma página (uma para visualização no navegador e uma para impressão), você preferiria que a versão de impressão fosse excluída do rastreamento, caso contrário você corre o risco de ter uma penalidade por conteúdo duplicado. Além disso, se você tiver dados sensíveis em seu site que você não quer que o mundo veja, também prefere que os mecanismos de pesquisa não indexem essas páginas (embora nesse caso a única maneira segura de não indexar dados confidenciais seja mantê-los offline em uma máquina separada). Além disso, se você quiser eliminar espaço de seu servidor, excluindo imagens, folhas de estilo e javascript de indexação, você também precisa de uma maneira de dizer para o Google para se manter longe desses itens.
Uma maneira de dizer aos motores de busca evitar que arquivos e pastas em seu site sejam indexados é com o uso do metatag Robots.
Mas como nem todos os motores de busca lêem metatags, o metatag Robots pode simplesmente passar despercebido. Uma maneira melhor de informar os motores de busca sobre sua vontade é usar um arquivo robots.txt.
O que é Robots.txt?
Robots.txt é um arquivo de texto (não html) que você coloca no seu site para informar aos robôs de pesquisa quais páginas você gostaria que eles não visitassem. O Robots.txt não é de forma obrigatória para os motores de busca, mas geralmente os motores de busca obedecem o que lhes é pedido para não fazer. É importante esclarecer que o robots.txt não é uma forma de impedir que os mecanismos de pesquisa rastreiem o seu site (ou seja, não é um firewall ou um tipo de proteção por senha) e o fato de você colocar um arquivo robots.txt é algo como colocando uma nota como “Por favor, não entre” em uma porta desbloqueada – por exemplo, você não pode impedir ladrões de entrar, mas os caras bons não abrem para a porta e entrar. É por isso que dizemos que se você tiver realmente dados sensíveis, é muito ingênuo confiar em robots.txt para protegê-lo de ser indexado e exibido nos resultados de pesquisa.
A localização do robots.txt é muito importante. Deve estar no diretório principal porque, caso contrário, os agentes de usuários (mecanismos de pesquisa) não conseguirão localizá-lo – eles não pesquisarão o site inteiro para um arquivo chamado robots.txt. Em vez disso, eles olham primeiro no diretório principal (ou seja, http://mydomain.com/robots.txt ) e se eles não encontrá-lo lá, eles simplesmente assumem que este site não tem um arquivo robots.txt e, portanto, eles adicionam tudo o que encontrar ao longo do caminho. Então, se você não colocar o arquivo robots.txt no lugar certo, não se surpreenda que os motores de busca indexem todo o seu site.
O conceito e a estrutura do robots.txt foi desenvolvido há mais de uma década e se você estiver interessado em saber mais sobre isso, visite http://www.robotstxt.org/ ou você pode ir direto para o Standard for Robot Exclusion pois, neste artigo, trataremos apenas dos aspectos mais importantes de um arquivo robots.txt.
Estrutura de um arquivo Robots.txt
A estrutura de um robots.txt é bastante simples (porém, nem tão flexível) – é uma interminável lista de agentes de usuário e arquivos e diretórios desativados.
Basicamente, a sintaxe é a seguinte:
User-agent:
Disallow:
“User-agent” são rastreadores de mecanismos de busca e não permitem : lista os arquivos e diretórios a serem excluídos da indexação. Além das entradas “user-agent:” e “disallow:”, você pode incluir linhas de comentário – basta colocar o sinal # no início da linha:
#Todos os agentes do usuário são proibidos de ver o diretório / temp.
User-agent: *
Disallow: /temp/
As armadilhas de um arquivo Robots.txt
Quando você começa a criar arquivos complicados – ou seja, você decide permitir que diferentes agentes de usuários acessem diretórios diferentes – os problemas podem começar, se você não prestar especial atenção às armadilhas de um arquivo robots.txt. Erros comuns incluem erros tipográficos e diretivas contraditórias. Os erros tipográficos são agentes de usuário com erros ortográficos, diretórios, colunias incompletas após User-agent e Disallow, etc.
Os erros podem ser complicados de encontrar, mas em alguns casos, as ferramentas de validação ajudam.
O problema mais sério é com erros lógicos. Por exemplo:
User-agent: *
Disallow: /temp/
User-agent: Googlebot
Disallow: /images/
Disallow: /temp/
Disallow: /cgi-bin/
O exemplo acima é de um robots.txt que permite que todos os agentes acessem tudo no site, exceto o diretório / temp. Até aqui está tudo bem, mas mais tarde há outro registro que especifica termos mais restritivos para o Googlebot. Quando o Googlebot começar a ler o arquivo robots.txt, verá que todos os agentes do usuário (incluindo o próprio Googlebot) são permitidos em todas as pastas, exceto / temp /. Isso é suficiente para que o Googlebot saiba, por isso não vai ler o arquivo até o final e irá indexar tudo, exceto / temp / – incluindo / images / e / cgi-bin /, que você acha que lhe disse para não tocar. Você vê, a estrutura de um arquivo robots.txt é simples, mas ainda erros graves podem ser feitas facilmente.
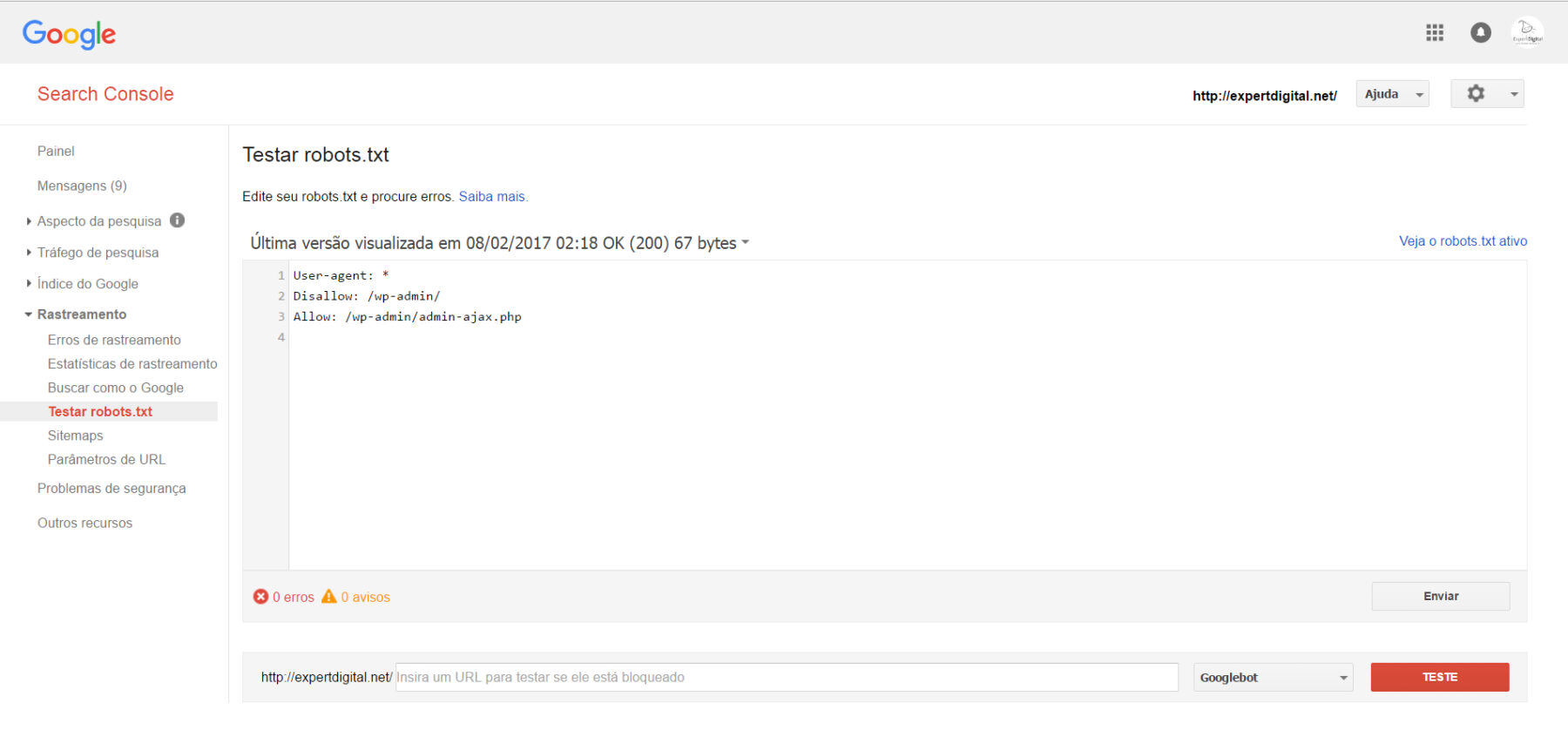
Enviar o robots.txt atualizado para o Google (Google Search Console)
1. Clique em Enviar no canto inferior esquerdo do editor de robots.txt. Essa ação abre uma caixa de diálogo “Enviar”.
2. Faça o download do código robots.txt editado na página da ferramenta Testar robots.txt clicando em Download na caixa de diálogo “Enviar”.
3. Faça o upload do novo arquivo robots.txt para a raiz do domínio como um arquivo de texto chamado robots.txt (o URL para o arquivo robots.txt deve ser /robots.txt).
Como instalar o Search Console (Webmaster Tools): expertdigital.net/como-instalar-o-search-console-webmaster-tools/
Se você não tiver permissão para fazer o upload dos arquivos na raiz do domínio, entre em contato com o gerente do domínio para fazer alterações.
Por exemplo, se a página inicial do seu site residir em subdomain.example.com/site/example/, provavelmente não será possível atualizar o arquivo robots subdomain.example.com/robots.txt. Nesse caso, você precisa entrar em contato com o proprietário de example.com/ para fazer as mudanças necessárias no arquivo robots.txt.
4. Clique em Verificar versão publicada para confirmar se o robots.txt publicado é a versão para indexação no Google.
5. Clique em Enviar versão publicada para notificar o Google que foram feitas modificações no seu arquivo robots.txt e solicitar a indexação do Google.
6. Verifique se a versão mais recente foi indexada corretamente pelo Google. Para isso, atualize a página do navegador a fim de renovar o editor da ferramenta e conferir o código do robots.txt publicado. Depois de atualizar a página, clique no menu suspenso acima do editor de texto para visualizar o timestamp em que o Google detectou a versão mais recente do seu arquivo robots.txt pela primeira vez.
Se você quiser saber mais sobre o que é o Search Console (Webmaster Tools), conheça o curso de Google Search Console (Webmaster Tools) da Expert Digital, lá você terá informações e um passo a passo para executar suas ações.

Link para o curso – https://expertdigital.net/curso-de-marketing-digital-para-iniciantes-gratuito/
Curso de Google Console Search (Webmaster Tools): https://expertdigital.net/curso-de-search-console/
Gostou? Essa é só uma pequena amostra do que a Expert Digital irá oferecer a você.
Eu adoraria saber a sua opinião sobre o conteúdo através de um comentário logo abaixo.
E caso ele tenha sido útil para você, aproveite para compartilhá-lo com um amigo ou uma amiga que precise de dicas como essas, mostrando o que é o Search Console (Webmaster Tools).
Forte Abraço e até o próximo artigo!



